Java 并发世界的金字塔体系
进程、线程、管程
进程Porcess:资源盒子
进程是操作系统分配资源的最小单位。它是内核为你程序画的一块地盘。每个进程都有自己独立的虚拟地址空间、文件描述符和安全上下文。
- 进程的精髓在于隔离。它假设所有的程序都是潜在的破坏者,所以给每个程序一套“皇帝的新衣”(虚拟内存),让它们觉得拥有整个物理内存,实则互不干涉。
- 进程是昂贵的。创建它意味着内核要为你写一套全新的账本(页表),这种 “主权独立” 的代价就是切换时的龟速。
线程Thread:CPU 流水线
线程是 CPU 调度的最小单位。它不是资源拥护者,它只是跑在进程地盘里的一段指令序列。它共享进程的所有资源,只自带一套极其寒酸的寄存器和栈。
- 线程的精髓在于压榨。它是为了解决 CPU 速度远超 IO 速度的尴尬。既然等数据太慢,就让 CPU 在同一个进程的几个任务里来回横跳。
- 线程是危险的。它没有隐私,和同僚共用一块内存。这意味着一个线程写错一个指针,整个进程就当场暴毙。它是追求效率的极致,也是混乱的根源。
管程 Monitor:并发契约
管程是一种将共享资源和同步逻辑封装在一起的结构化机制。它不是底层的硬件指令,而是编程语言层面(如 Java)为了防止程序员把多线程写崩而设计的一套规则。 管程的精髓在于封装。它把 “怎么锁”、“谁排队”、“满足什么条件能进”全部藏在黑盒里。你只需要调用方法,它保证内部逻辑是串行的。
在 Java 的世界,管程的物理基础是 ObjectMonitor,在 JVM(HotSpot)层面,每个 Java 对象生来就带着一个隐藏的 ObjectMonitor 结构。这就是为什么 Java 敢说 “万物皆对象”,因为 “万物皆可作为锁”。当你写下 synchronized(obj) 时,你其实是在尝试获取这个对象背后的 Monitor 所有权。Java 管程的本质是由两套 “排队机制” 组成的独裁机构:
- Entry Set(入口等待池):这是一个 “死磕到底” 的区域。当线程 A 占用了对象的 Monitor,线程 B、C 只能在这里卡着。它们的状态是 BLOCKED,唯一的活计就是盯着那把锁,一旦 A 释放,它们就上去疯抢。
- Wait Set(条件等待池):这是一个 “中场休息” 的区域。当你调用 obj.wait() 时,线程会主动交出锁并进入这里,状态变为 WAITING。它不再抢锁,直到有人喊一声 notify()。
Java 管程最犀利的地方在于它实现了 “数据与同步的合体”,把共享变量和操作代码(synchronized 方法)关进了一个盒子里。程序员不需要手动管理 lock() 和 unlock()。JVM 保证了:只要你进入这个方法,你就获得了独裁权;只要你离开(无论是正常返回还是抛出异常),独裁权自动交还。
早期的 Java 管程是真正的“重量级”锁,每次加锁都要找操作系统讨要互斥量(Mutex),慢得令人发指。现在的 Java 管程极其狡猾。它会先尝试 偏向锁(以为只有你一个人来)、再尝试 轻量级锁(自旋,不阻塞 CPU),实在抢不过了才会膨胀成真正的 重量级管程。这反映了 JVM 的设计哲学——尽可能推迟真正的同步代价。
所以概括起来,Java 的管程就是一种 “懒人保险”。它利用对象头里的几位元数据,把混乱的线程竞争变成了有序的、自动化的入场券管理系统。
线程安全问题怎么来的?
什么是线程安全?
对于你写的程序,你的本意是 ”不管怎么折腾,结果应该总是符合预期“。如果你的代码在单线程下跑得好好的,丢到多线程环境里,不需要额外的同步手段,它的行为依然是正确的,那它就是线程安全的。线程安全不是代码的属性,而是对共享状态访问权限的管控。
为何会有线程安全问题?
之所以存在线程安全问题,主要有三个祸根:
- 原子性(Atomicity)问题: 比如你以为 count++ 是一步到位,其实 CPU 把它拆成了 “取值、加一、回写” 三步。在这三步中间,另一个线程插一脚,数据就脏了。(本质是你以为的原子操作中间被切断了)
- 可见性(Visibility): 为了快,每个 CPU 核心都有自己的 L1/L2 缓存。线程 A 修改了变量还在自己的缓存里揣着,线程 B 看到的还是老掉牙的数据。(本质是核心和多线程环境下的信息不对称)
- 有序性(Ordering): 编译器和 CPU 都是 “迟到早退” 的优化狂。它们为了优化性能,自作聪明地调整你指令的顺序(重排序),只要单线程执行结果不变,它们觉得怎么排都行。在单线程看来没问题,但在多线程眼里就是灾难。(本质是线程的剧本被重排了)
Java 线程安全的三大路径
Java 的治理思路非常清晰:要么硬刚,要么躲避,要么靠制度。
- 互斥同步(阻塞同步):硬刚派:这就是我们上面说的管程(Monitor)逻辑。典型的代表就是 synchronized 和 ReentrantLock。它的逻辑很简单,“谁也别争,一次只能进一个”。它解决了原子性、可见性和有序性,但是这种方式也最重,线程挂起和唤醒需要从用户态切换到内核态,CPU 表示很累。
- 非阻塞同步:乐观派:典型的代表是 CAS(Compare-And-Swap)操作,如 AtomicInteger。它表示 “我不加锁,我直接去改。如果改的时候发现值变了,说明有人动过,那我就重试(自旋)”。这是一种乐观锁。它假设冲突不常发生,利用底层硬件指令(如 cmpxchg)来保证原子性,避免了线程切换的开销。
- 无同步方案:躲避派:典型的代表就是 ThreadLocal、不可变对象(Immutable)。它的逻辑是 “既然抢资源会出事,那咱们干脆别共享了,不共享才是最高级的同步”。
Java 并发世界的金字塔结构
Semaphore / CompletableFuture
“程序员的舒适区:直接下达语义指令”
ThreadPoolExecutor / BlockingQueue
“并发脊梁:解决状态管理与排队逻辑”
“物理契约:禁飞区与原子手术刀”
- 底层负责“不被打断”
- 中层负责“有序排队”
- 顶层负责“优雅好用”
如果把 Java 并发编程比作一座 “镇妖塔”,那么每一层都在试图镇压那头名为 “不确定性” 的怪兽。我们可以将这个结构进一步提炼为:地基(机制)、骨架(抽象)、工具(接口)。
底层:物理世界的契约
这是金字塔最厚重的一层,直接跟 CPU 指令、内存屏障(Memory Barrier)和操作系统内核打交道。核心组件包括: volatile、CAS (Unsafe)、LockSupport、synchronized (Monitor)。本质是解决 “肉身” 的局限,这个所谓的肉身指的就是昂贵、迟钝且自作聪明的物理硬件(CPU、缓存、内存)。包括以下三个层面:
- 可见性的问题:
- 肉身局限: CPU 太快,内存太慢。
- 为了不让 CPU 闲着,每个核心都有自己的 L1/L2 高速缓存(自己的 “小灶”)。线程 A 在核心 1 修改了变量,它可能只改了自己缓存里的副本,根本没打算立刻告诉主内存。线程 B 在核心 2 读到的还是老数据。
- 底层手段:
volatile。它是一道肉身必须循序的强行同步指令,表示数据一旦修改,立即刷回主存;一旦读取,必须废弃缓存直接看主存。
- 原子性问题:
- 肉身局限:代码指令对应的多个硬件指令是 “碎” 的。
- 比如你以为 i++ 是一个动作,但在 CPU 眼里,这是 “从内存取值”、“放进寄存器加一”、“写回内存” 三个动作。而真相是在这三步的间隙,另一个线程可能已经把值改了。你的 “肉身” 无法保证这三步像瞬移一样一气呵成。
- 底层手段:
CAS (Compare And Swap)。它直接调用 CPU 的原子指令(如 x86 的 LOCK CMPXCHG),在硬件层面锁住北桥信号或缓存行,强行让这三步变成一个不可分割的原子操作。
- 有序性问题:
- 肉身局限:编译器和 CPU 都是 “迟到早退” 的优化狂。
- 在多线程眼里,顺序就是命。比如“先初始化对象,再赋值给变量”,如果被 CPU 优化成“先赋值变量(此时还是半成品),再初始化对象”,另一个线程拿到的就是一个畸形的、不可用的废品。
- 底层手段:
Memory Barrier(内存屏障)。这是在代码里插下的 “定海神针”,告诉 CPU,不管你怎么优化,屏障前后的指令绝对不能越雷池一步。
所以综合来看,这些底层这些金字塔最底层组件存在的意义,就是给脆弱、混乱的物理硬件打补丁。它们通过强制性的协议,在冰冷的硅片上强行构建出一个符合人类逻辑的、可靠的运行环境。正如我们在金字塔中看到的,如果没有底层这些 “对抗肉身局限” 的原语,中层的 AQS 和顶层的工具类都只是建立在流沙上的幻影。
中间层:工业化骨架
这一层不再直接玩弄硬件,而是把底层的零散工具组装成 通用的模板。核心组件包括:AQS 、ThreadPoolExecutor、BlockingQueue。本质是解决 “排队” 的艺术。
- AQS 是灵魂: 它把底层那些零散的 CAS 和 LockSupport 封装成了一个极其精妙的 状态管理机。它只管两件事:谁拿到了令牌(State),没拿到的去哪儿排队(队列)。
- 线程池是管家: 它解决了线程的 “生死轮回” 成本。它不再是一个个去雇佣劳动力,而是建立了名为 “线程池” 的工厂。
这一层是体现出了抽象的强大力量。如果没有 AQS,每个开发者都要去手写复杂的排队和挂起逻辑,那 Java 早就因为死锁遍地而崩盘了。
顶层:程序员的舒适区
这是我们每天在业务代码里直接调用的 “精装房”。核心组件包括: ReentrantLock、CountDownLatch、Semaphore、CyclicBarrier、CompletableFuture 等等。它的本质是:解决 “语义” 的表达。
- 你不需要懂 AQS 的双向链表,你只需要调用 lock.lock() 就能获得安全感。
- 你不需要懂如何唤醒一群线程,你只需要 latch.await() 就能优雅地等待任务结束。
这一层是语义化的结晶。它把复杂的并发逻辑翻译成了人类听得懂的语言:“重入”、“闭锁”、“信号量”。
线程刨根问底
线程的底层模型
先抛出一个送命的问题:“Java 运行一个线程到底有几种方式?” 如果只看表面,结果可能五花八门。比如大多数教科书和面试题的答案,它们其实只是包装盒的不同:
- 继承 Thread 类:最原始的野路子。
- 实现 Runnable 接口:最常用的解耦路子。
- 实现 Callable 接口:带返回值的进阶路子(配合 FutureTask)。
- 线程池(ExecutorService):工业化的流水线路子。
- CompletableFuture / ForkJoin:现代异步编程的高级路子。
但这些都只是在应用层换了种姿势把任务交给系统,算不上本质。寻根究底去翻开 JDK 的源码,盯着 Thread 里的那个 start() 方法看,你会发现无论你用哪种方式,最终都会汇聚到这行代码:
1 | private native void start0(); |
这个 native 关键字就是 “次元壁”。它意味着 Java 已经把指挥权交给了 JVM(C++ 实现),而 JVM 则通过 pthread_create(Linux 下)去向 操作系统内核 讨要一个真正的线程。所以在 Java 层面,运行一个线程 只有 Thread 类这一个唯一入口。Runnable 和 Callable 只是线程任务的定义方式的不同,底层本质上都是一样的。
在主流的 HotSpot JVM 中,Java 线程与操作系统线程(内核线程)的关系是 1:1。new Thread() 并 start(),JVM 内部就会通过 C++ 调用操作系统底层的 pthread_create(Linux)或 CreateThread(Windows)。Java 线程的 “真身” 就是一个轻量级进程(LWP)。既然是 1:1,那么谁来决定哪个线程先跑、跑多久?全是操作系统说了算。
JVM 对线程调度采取的是 “甩手掌柜” 模式。它完全服从操作系统的 抢占式调度(Preemptive Scheduling)。
- 操作系统的工作: 它把 CPU 的时间分成极其微小的 “时间片”(几毫秒)。它像个冷酷的裁判,哨声一响,当前线程必须打住,保存现场(上下文切换),换下一个线程上场。
- Java 的无能为力: 你在 Java 里调用 Thread.
setPriority()想提高优先级?对不起,那只是给 OS 的一个“建议”。OS 可能会参考,也可能完全无视,因为它要统筹全局(包括你的浏览器、网速监控、输入法等所有进程)。
虽然是抢占式,但 Java 提供了几个看似能“干预”调度的手段,其实本质很心酸:
Thread.yield():线程对着 OS 卑微地喊一句:“大哥,我不急,你要是手头有更重要的活儿,先紧着人家。” OS 听完点点头,然后可能反手又把 CPU 分给了这个线程(因为没有更合适的)。Thread.sleep():线程直接躺平:“我睡10毫秒,这段时间别烦我”。 这时OS才会真正把此线程踢出 “就绪队列”。
关键对接点:上下文切换(Context Switch),这是 JVM 与 OS 对接时最贵的动作。
- 保存现场: 把当前 CPU 寄存器里的值、程序计数器(PC)指向的代码位置,统统存到该线程私有的虚拟机栈里。
- 恢复现场: 把下一个线程之前存好的状态重新塞回 CPU。
上下文切换是纯粹的内耗,它不产生任何计算价值,却要消耗数千个 CPU 时钟周期。这就是为什么 “线程不是越多越好”——当线程多到一定程度,CPU 全忙着搬运 “现场” 了,根本没空干活。
因为 1:1 模型太重了!几千个线程就能把 OS 压垮。Java 21 推出了虚拟线程(Virtual Threads)的概念,这时虚拟线程变成了 M:N 模型。几万个虚拟线程(M)跑在几十个系统线程(N)上。JVM 终于夺回了一部分调度权。当一个虚拟线程遇到阻塞(比如查数据库),JVM 把它从系统线程上拽下来,换另一个上去,而不需要麻烦 OS 去做昂贵的上下文切换。
线程状态流转相关方法


sleep vs wait:谁才是真正的 “自私” ?
- sleep 是自私的:它就像一个占着茅坑睡觉的人。它虽然让出了 CPU(不干活了),但它手里死死攥着锁(Monitor)。别人进不来,只能干等。
- wait 是大度的:它知道自己现在干不了活,于是主动把锁交出来(释放 Monitor),去旁边休息室(WaitSet)坐着。本质上, sleep只是时间层面的调度,wait 是同步层面的协作。
yield:最卑微的 “建议”
调用 yield 就像是在挤公交车时说:“我不急,大家先上”。操作系统可能觉得剩下的那个人(由于优先级或其他原因)还不如你,结果 CPU 兜了一圈,秒回到了你手里。它不保证一定切换成功。
join:基于 wait 的套娃
很多人以为 join 是什么高深的黑科技。其实看源码你会发现,它本质上就是一个 “死循环 wait”:
1 | while (isAlive()) { |
当线程执行结束(死亡)时,JVM 会自动调用一次 notifyAll(),此时 join 所在的线程就会被唤醒。
park/unpark:工业级的 “定身术”
这是 AQS 最喜欢的底层原语。
- 优势: 它不需要放在 synchronized 块里,因为它不依赖 Monitor。它通过一个许可(Permit)来工作。
- 神技: unpark 甚至可以先于 park 执行!就像提前给了一张进门条,线程调用 park 时直接通过,不会阻塞。
线程六大状态之间的流转
JVM 的这六种状态不是静止的横截面,而是一场由底层原语驱动的动态位移。我们可以把这场球赛看作是从 “出生” 到 “火化” 的过关游戏:
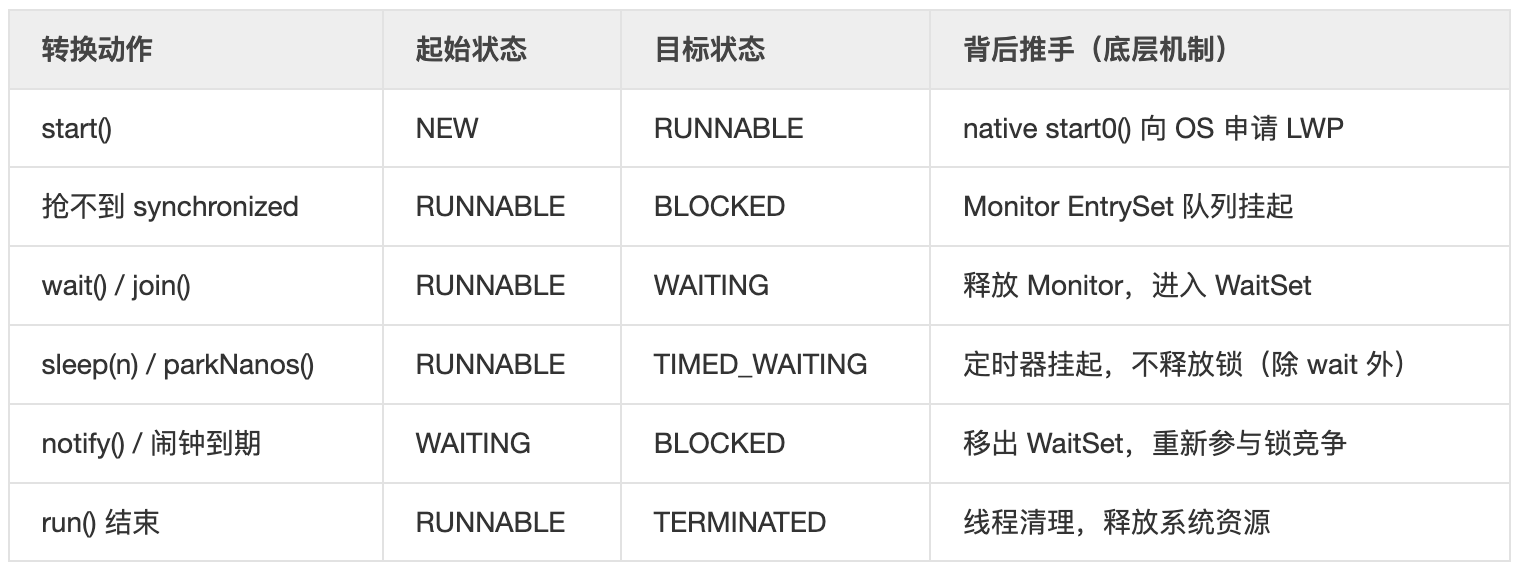
出生与准备:NEW ➔ RUNNABLE
- 动作:new Thread() 之后,它只是个 Java 对象(NEW)。一旦执行 start(),它就进入了 RUNNABLE。
- 真相:在 JVM 眼里,只要你拿到了 CPU 时间片,或者正在排队等时间片,你都叫 RUNNABLE。这就是为什么这个状态在 OS 层面其实包含了 “就绪” 和 “运行中”。
遭遇独裁者:RUNNABLE ➔ BLOCKED
- 触发:撞上了 synchronized 墙。
- 本质:线程想进 Monitor 的入口(Entry Set),但里面已经有个 “独裁者” 在占着。此时线程被操作系统挂起,彻底失去 CPU 执行权。
- 踢球者:那个占着锁不撒手的线程。
- 主动禅让:RUNNABLE ➔ WAITING / TIMED_WAITING,这是程序员最常玩“踢皮球”的地方:
- 无限期等待 (WAITING):调用 obj.wait()、thread.join() 或 LockSupport.park()。 线程主动交出锁,进入休息室(Wait Set)。没有人叫它(notify),它能在那儿等到天荒地老。
- 限期等待 (TIMED_WAITING):调用 sleep(n)、wait(n)、parkNanos()。给自己定个闹钟。闹钟响了或者被人叫醒,都能回去继续抢球。
- 重回赛场:WAITING ➔ BLOCKED ➔ RUNNABLE
- 这是一个最容易被忽视的细节。当你调用 notify() 唤醒一个 WAITING 线程时,它并不是直接回到 RUNNABLE。
- 它只是从休息室(Wait Set)挪到了门口(Entry Set)。它必须先变成 BLOCKED 去重新抢那把锁,抢到了,才能变成 RUNNABLE。
- 终点:TERMINATED
- 触发:run() 方法执行完,或者抛出了没捕获的异常。
- 本质:“肉身” 已毁,无法复生。你不能对一个 TERMINATED 的线程再次调用 start(),否则它会反手给你一个 IllegalThreadStateException。
在操作系统的教科书里有 “挂起(Suspend)”,但 Java 的六大状态里没有。因为 Java 把所有 “能跑但没跑” 的情况都封死在了 RUNNABLE 内部(由 OS 调度),或者归类到了 WAITING/BLOCKED(由 JVM 逻辑触发)。这种设计是为了跨平台抽象。Java 不想让你关心 OS 是怎么切时间片的,它只让你关心:你是被锁卡住了,还是在等信号,还是在睡觉。所有的线程状态流转,本质上都是在 “锁【资源】” 和 “时间片【CPU】” 之间的权力交接。
thread.sleep 刨根问底
Java层面:JVM的native接口
1 | // java.lang.Thread |
1 | Thread.sleep(1000) // Java层 |
Thread.sleep() 的最终实现是通过将当前线程/进程设置为可中断的睡眠状态,并从运行队列中移除,然后由内核的定时器机制在指定时间后重新将其加入运行队列。这是一个涉及 用户态-内核态切换、进程调度、定时器管理和中断处理 的复杂过程,但最终都基于操作系统的进程/线程调度原语。sleep 涉及完整的上下文切换和内核态切换,这正是它成本较高的根本原因。
上下文切换的具体内容:
1 | X86_64架构的上下文主要包括: |
Linux内核中的上下文保存:
1 | // arch/x86/include/asm/processor.h |
1 | # 时间开销分解 |
短时 sleep 的优化:
1 | // HotSpot的实际优化:短时间用自旋 |
实际测试:感受上下文切换的开销
1 | public class SleepOverhead { |
1 | Sleep总耗时: 1296003954 ns (平均: 1296003 ns/次) |
obj.wait-notify 刨根问底
基本原理
Object.wait()是Java并发编程的基石之一,它的底层实现比 Thread.sleep()更复杂,因为它必须与锁(synchronized)和条件变量配合。一句话概括 obj.wait() 是线程在持有锁的前提下,为了等待某个逻辑条件,主动释放锁所有权、进入内核态挂起、并将自己托管在对象的等待池中,直到被唤醒并重新竞争到锁为止的协作机制。下面让我们从Java层一直刨到Linux内核。
Java层:使用条件和限制
1 | synchronized (obj) { // 1. 必须先获取对象锁,否则抛出IllegalMonitorStateException。 |
JVM实现层:对象头与ObjectMonitor
对象的内存布局:
1 | +------------------------+ |
Mark Word在不同状态下的内容(64位JVM):
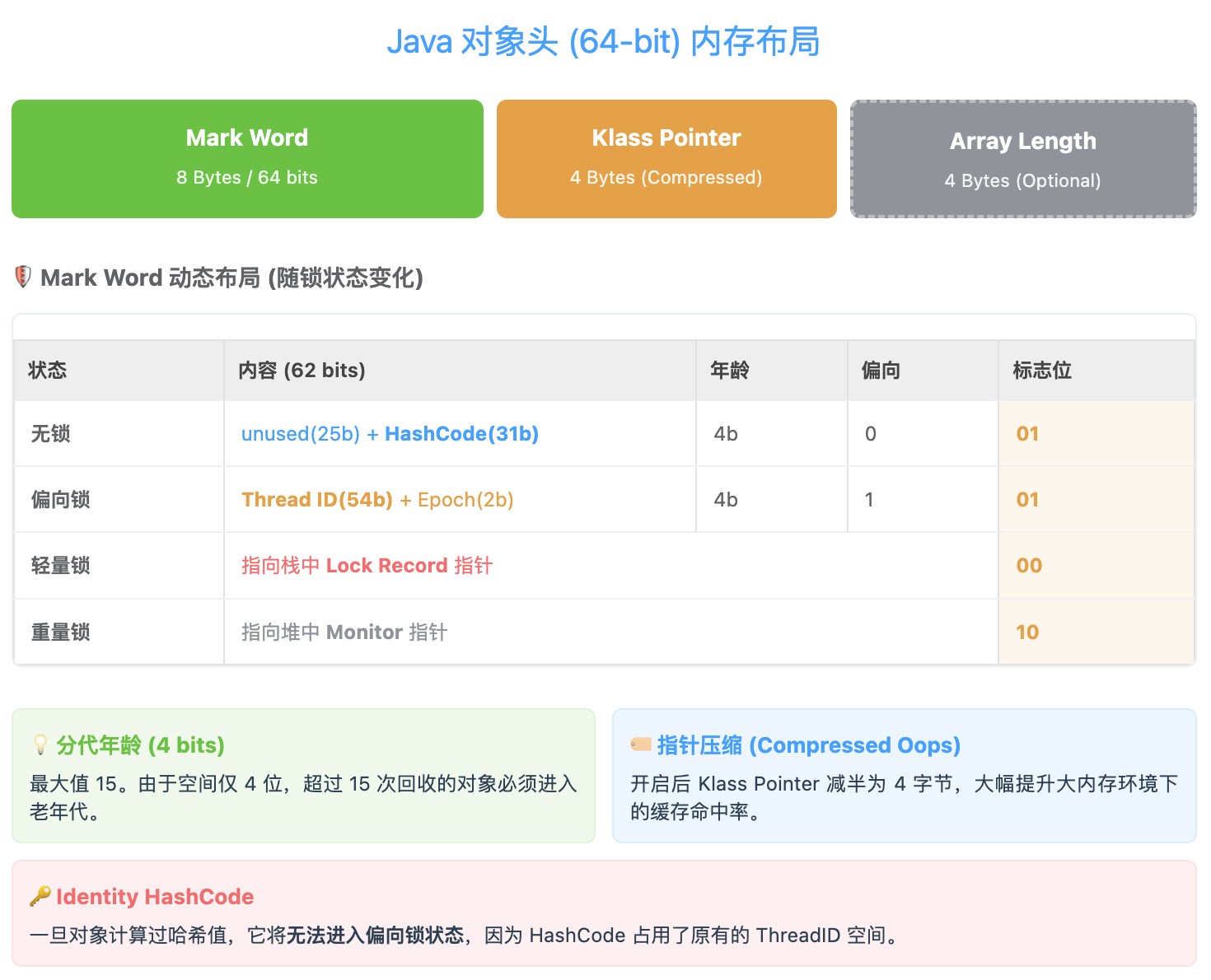
ObjectMonitor结构:当竞争激烈时,偏向锁升级为重量级锁,对象头中的 Mark Word 指向 ObjectMonitor。当你调用 obj.wait() 时,JVM 第一件事就是看一眼对象头。对象头就像是一个 “中转站”。线程通过对象头找到 ObjectMonitor,再通过 ObjectMonitor 找到 _WaitSet(那个存放等待者的池子)。
- 锁标志位(Lock Flag): 对象头最后两位(10)告诉 JVM:“我已经是重量级锁了,去
ObjectMonitor里谈吧。” - 撤销偏向(Revoke Bias): 如果对象正处于偏向锁状态,wait 操作会强行撤销偏向,将其膨胀为重量级锁。因为偏向锁根本没有 “等待池” 的概念,它太简陋了。
1 | // hotspot/src/share/vm/runtime/objectMonitor.hpp |
完整调用链
从Java到JVM
1 | // jdk/src/share/vm/prims/jvm.cpp |
ObjectSynchronizer::wait
1 | // hotspot/src/share/vm/runtime/synchronizer.cpp |
核心分水岭:ObjectMonitor::wait
1 | // hotspot/src/share/vm/runtime/objectMonitor.cpp |
操作系统的等待机制:ParkEvent
1 | // hotspot/src/share/vm/runtime/park.hpp |
Linux内核层面,ParkEvent最终通过futex实现:
1 | // 最终调用链: |
notify/notifyAll的实现
1 | void ObjectMonitor::notify(TRAPS) { |
从等待中恢复后获取锁
1 | void ObjectMonitor::enter(TRAPS) { |
完整流程总结:
1 | Java: obj.wait() |
总结这个调用链:
- Java 层:负责表达业务意图(我要等)。
- JVM 抽象层 (ObjectMonitor):负责管理排队逻辑(谁在等,锁给谁)。可以浓缩为这三步:
- 入队登记(WaitSet):JVM 为当前线程创建一个 ObjectWaiter 节点,把它塞进该对象专属的 _WaitSet(等待池)。这是一个专门存放“等信号的人”的单向链表。
- 净身出户(释放锁):这是最关键的一步。JVM 会调用 exit() 释放当前持有的 Monitor。如果不释放,别的线程拿不到锁,就没法调 notify(),你就会死在等待中。
- 内核挂起(真正停下):通过 pthread_cond_wait 触发 Linux 内核的 futex(FUTEX_WAIT) 系统调用。内核把该线程状态改为 TASK_INTERRUPTIBLE,并从 CPU 调度队列里踢出去。此时,线程彻底 “断电”。
- OS 平台层 (ParkEvent/pthread):负责抹平不同系统的差异。
- 内核层 (futex/schedule):负责真正的肉身停顿(让出 CPU)。
当另一个线程调了 notify(),它会触发 futex(FUTEX_WAKE)。
- 复活: 线程被内核重新设为 TASK_RUNNING,回到 JVM。
- 二次挑战: 醒来后的第一件事不是执行代码,而是调用
ObjectMonitor::enter()。它必须重新和 EntryList 里的线程去抢锁。抢不到?那就去BLOCKED状态排队。抢到了才能从wait()方法里跳出来,继续执行你 Java 代码的下一行。
一些优化
1)自适应自旋:
在旧版 JVM 里,没有自适应自旋(Adaptive Spinning),一抢不到锁就直接下潜到内核态 futex,成本极高。现在:TrySpin 逻辑会观察历史。如果这个锁上次自旋几下就拿到了,这次它就会多转一会儿,试图在用户态就解决战斗,坚决不下潜到内核。
1 | // ObjectMonitor的自旋逻辑 |
2)偏向锁优化:
对于没有竞争的情况,JVM使用偏向锁避免重量级操作:
- 第一个线程访问:对象头设置为偏向模式,记录线程ID
- 同一线程再次访问:检查线程ID匹配,直接进入临界区
- 其他线程访问:升级为轻量级锁(CAS竞争)
- 竞争激烈:升级为重量级锁(使用ObjectMonitor)
LockSuppport.park-unpark
基本原理
在 Java 并发金字塔的底层,park 和 wait 虽然最终都让线程 “躺平”,但它们的 户口本 和 执行细节 完全不同。
park 的底层逻辑不是基于 “排队”,而是基于一个 “二元信号量”(只有 0 和 1 两个状态的计数器)。每个线程都有一个关联的 Permit。
- park():如果 Permit 为 1,则将其设为 0 并立即返回;如果为 0,则阻塞。
- unpark():将 Permit 设为 1(无论之前是多少,最高只能是 1)。
- 神技: unpark 可以先于 park 执行。如果在线程 park() 之前,你先调了 unpark(),那么线程下次执行 park() 时不会阻塞,而是直接消费掉这个 “许可证” 并继续跑。而 wait/notify 绝对做不到这一点。如果你先调 notify 后调 wait,线程会死等,因为信号已经丢了。
底层调用链条
当你调用 LockSupport.park(),它的穿透路径如下:
Java 层:LockSupport.park()
JNI 层:调用 Unsafe.park(boolean isAbsolute, long time)
JVM 层 (HotSpot):每一个 Java 线程在 JVM 内部都有一个 Parker 对象。
1
2
3
4class Parker : public os::PlatformEvent {
volatile int _counter ; // 许可证计数器
...
}OS 层 (Linux):最终通过 pthread_mutex 和 pthread_cond_wait 实现。内核层面依然是 futex 系统调用,将线程放入等待队列并切出 CPU。
LockSupport.park()的本质是:
- 基于许可的线程阻塞原语:通过_counter实现 “一次性通行证”
- 最轻量的阻塞机制:不需要锁,不涉及对象监视器
- 可重入的等待/唤醒:unpark给许可,park消费许可
- 平台统一的抽象:Linux用pthread条件变量,Windows用Event对象
- Java并发框架的基石:AQS、Lock、同步器都构建在它之上
基本的使用 API
1 | // 阻塞当前线程 |
park 与 wait 的比较
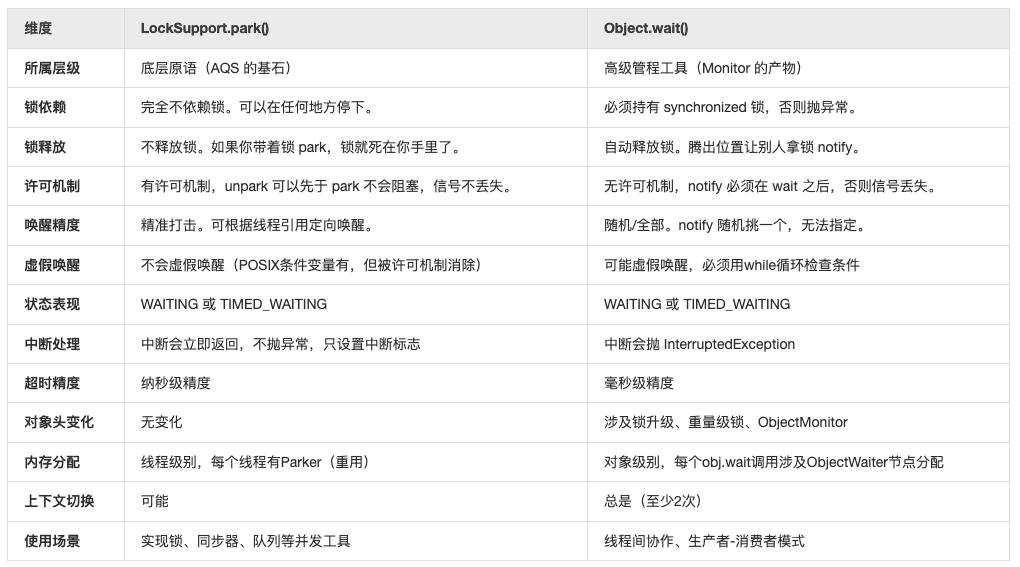
性能对比:
- LockSupport.park/unpark: 约 20-50 ns/op
- Object.wait/notify: 约 100-200 ns/op
内存开销:
- LockSupport.park/unpark:小,每线程一个Parker
- Object.wait/notify:大,涉及对象头和 ObjectMonitor
总而言之:
- wait 是 “团伙协作”:必须有带头大哥(Monitor 锁),大家在同一个休息室(WaitSet)里按规矩来。
- park 是 “特种作战”:不需要指挥官,每个士兵自带一张许可证。想停就停,想走就走,主打一个精准、独立、轻量。
为何AQS选park而非wait
如果你去读 ReentrantLock 或 CountDownLatch 的源码(中层框架层),你会发现它们全是基于 LockSupport.park()。
- 解耦: AQS 需要自己管理 state(比如锁的次数),如果用 wait,它必须强行依赖 synchronized 关键字,这在逻辑上是重复造轮子且低效的。
- 灵活: AQS 的队列管理非常复杂(双向链表、取消节点等),park/unpark 的这种 “按人头唤醒”的能力,比 notify 那种 “随缘唤醒” 要高效得多。
- 避免死锁: 因为 unpark 可以在 park 之前调用,这从根本上规避了由于执行顺序导致的永久阻塞问题。
park 和 wait 的殊途同归
殊途之处
表现在在到达内核之前的 “仪式感”,虽然 “刹车” 的效果是一样的,但 踩刹车之前的动作 完全不同:
Object.wait():沉重的 “管程协议”
- 硬件操作:它必须操作对象头(Mark Word),这涉及到多次内存寻址。
- 内存屏障:为了保证锁的释放能被其他 CPU 核心看见,它会触发昂贵的 StoreLoad 屏障(如 x86 的 lock 前缀指令),强行冲刷 CPU 写缓冲区。
- 逻辑损耗:在调用内核 futex 之前,JVM 还要维护 WaitSet 链表。
LockSupport.park():轻量的 “信号量协议”
- 硬件操作:它只检查一个位于 Parker 对象中的 _counter(许可证)。
- 内存操作:这通常只是一个简单的 CAS (Compare And Swap) 操作。如果没有许可证,直接调 futex。
- 逻辑损耗:几乎没有。它不需要去翻对象头,也不需要管理复杂的 Monitor 状态机。
同归之处
相同的底层“刹车”原语:futex (Linux)
在现代 Linux 内核中,无论是 LockSupport.park() 还是 Object.wait(),最终几乎都会通过系统调用进入 futex (Fast Userspace Mutex) 逻辑,futex 是 Linux 系统中的一种同步机制,专门为多线程环境下的用户态与内核态交互而设计。
- 硬件表现:CPU 执行 SYSCALL 指令,从用户态陷入内核态。
- 内核动作:内核将当前线程的 task_struct 状态设置为 TASK_INTERRUPTIBLE(可中断睡眠),并将其从 CPU 的运行队列(Run Queue)中移除,放入一个由内核管理的等待队列(Wait Queue)。
- 结果:CPU 不再给这个线程分配时钟周期。从物理电平角度看,这个线程对应的指令流停滞了。
相同的硬件代价:上下文切换 (Context Switch)
由于 park 和 wait 都导致了线程挂起,硬件层面的开销是一致的:
- 寄存器保存:将当前 CPU 核心里的通用寄存器、程序计数器(PC)、栈指针(SP)等数值压入内核栈。
- TLB 刷新:如果切换到了不同进程的线程,还需要刷新页表缓存(TLB),这非常昂贵。
- 缓存冷启动:线程醒来后,它之前在 L1/L2 缓存里的数据可能已经被别人覆盖了,会产生大量的 Cache Miss。
小结
我们可以把这两种机制类比为 “停车”:
- Object.wait():就像是进入一个 收费停车场。
- 流程:你得先领卡(拿 synchronized 锁),登记车辆信息(对象头),然后把车停进指定的车位(WaitSet),最后熄火(futex wait)。
- 重启:有人在大厅喊你(notify),你得去排队取车,再交费出场(重新竞争锁)。
- LockSupport.park():就像是 在路边临时熄火。
- 流程:你看看兜里有没有通行证(Permit)。没有?直接熄火原地等待(futex wait)。
- 重启:有人递给你一张证(unpark),你直接打火走人。
在硬件指令集(如 MWAIT 或 HLT)层面,CPU 并不区分你是 park 还是 wait。它们唯一的区别在于:wait 是为了维护 Java 的同步语义而包裹了大量内存访问和逻辑判断的 “豪华版挂起”;而 park 是为了高性能并发框架设计的 “极简版挂起”。这也是为什么在金字塔中层(AQS)中,大神 Doug Lea 坚持使用 park——因为在底层硬件代价相同的情况下,应用层的逻辑越薄,性能就越接近物理极限。
Java内存模型 JMM
JMM是Java并发编程中最深刻、最易误解的概念。让我们从最底层开始,彻底理解它是什么、为什么需要它、以及它是如何工作的。
JMM 是怎么出现的?
第一是硬件的 “任性” 优化行为带来的并发问题
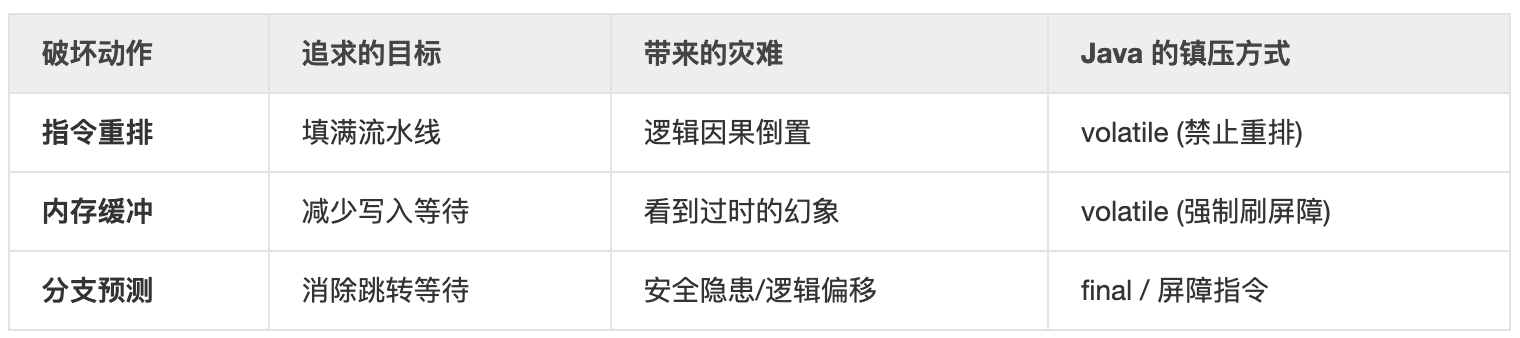
现代CPU为了性能优化,会做三件 “破坏顺序” 的事情,分别是:
- 编译器与处理器指令重排序(Instruction Reordering),对于它们来说,只要结果看起来对,过程随便换。CPU 发现你代码里的指令 A 和指令 B 互不依赖(比如 a = 1; b = 2;),它可能会先执行 B 再执行 A。
- 为什么要破坏? 如果执行 A 需要去遥远的内存取数(慢),而 B 的数据就在寄存器里(快),CPU 会为了不让流水线停顿,先去跑 B。
- 代价就是,在单线程下这很聪明;但在多线程下,如果 A 是 “初始化对象”,B 是 “把对象指向变量”,一旦顺序反了,另一个线程就会拿到一个 “半成品” 对象。
- 内存异步写入(Store Buffer & Invalidation Queue),意思大概就是 “我改了,但我还没告诉全世界”。CPU 核心并不是直接改内存,而是先改自己的 Store Buffer。
- 为什么要破坏? 这是因为写入主内存太慢了。CPU 核心把修改丢进 Store Buffer 后就立刻去干下一件事了。
- 代价就是,这破坏了内存可见性的顺序。线程 A 在核心 1 改了变量,线程 B 在核心 2 读到的还是旧值。在硬件层面,这表现为一种 “伪重排序”——看起来像是读指令跑到了写指令前面。
- 分支预测(Branch Prediction),大意是 “我猜你会走这条路,所以我先把路修好了”。遇到 if-else 时,CPU 不会死等判断结果,它会根据历史经验盲猜一个分支并提前执行。
- 为什么要破坏? 为了填满指令流水线。如果猜对了,性能起飞;如果猜错了,直接丢弃结果重新跑。
- 代价就是,这种 “先斩后奏” 破坏了代码逻辑的严格先后顺序。它可能导致某些本不该执行的敏感代码(如权限校验后的操作)在后台偷偷运行过。
现代 CPU 是 “结果导向型” 的骗子,它为了快可以瞒天过海;而 Java 的底层并发原语则是 “过程监督员”,通过插桩(屏障)强迫 CPU 回归老实的顺序执行。
第二是,为多样性的硬件内存模型提供统一的抽象
不同硬件平台的内存模型不同:
- x86/64 架构:TSO(全存储排序)内存模型,写操作不会重排序,但读操作可能重排序
- ARM/POWER 架构:弱内存模型,读和写都可能重排序
- SPARC 架构:RMO(宽松内存排序)内存模型,几乎允许所有重排序
- Alpha 架构,最弱模型,甚至允许 “写入后读取” 看到旧值
这就是JMM存在的根本原因:提供一个统一的抽象,让 Java 程序在所有硬件上都有确定的行为。
JMM 核心定义
正式定义
JMM是Java语言规范(JLS,Java Language Specification)第17章定义的一个正式规范,它规定了:
- 哪些行为是合法的:在多线程环境下,什么情况下线程能看到什么值
- 哪些重排序是允许的:编译器和CPU可以如何优化
- 同步操作的语义:
volatile、synchronized、final等如何影响内存可见性
关键抽象
JMM定义了两种内存和三种关系:
共享变量副本
共享变量副本
注:JMM 决定一个线程对共享变量的写入何时对另一个线程可见。
注:私有内存(工作内存)对应 CPU 寄存器和缓存;主内存对应硬件内存。
两种内存:主内存和工作内存,它们并不真实存在于物理内存中,而是一种逻辑抽象。
- 主内存 (Main Memory):它是所有线程共享的 “公共仓库”,所有的实例变量、静态变量都存储在这里。在物理层面,主内存通常涵盖了堆内存(Heap)和方法区(Method Area)中存储的实例字段、静态变量和数组元素等共享数据。
- 工作内存 (Working Memory):它是每个线程私有的 “独立办公室”,存储线程从主内存拷贝过来的变量副本。在物理上它可以对应,但不限于CPU的高速缓存(L1/L2/L3 Cache)、寄存器,甚至是编译器优化时的临时存储。
- 核心的规则⭐️:每个线程不能直接读写主内存,必须先在自己的工作内存里改完,再刷回主内存。线程间也无法互相访问对方的工作内存。
三种关系:JMM 的三大特性
- 原子性 (Atomicity):一个操作要么全部执行成功,要么全部执行失败,中间不可被中断。JMM 保证基本类型的读写是原子的。主要的镇压手段是
synchronized块或Lock。 - 可见性 (Visibility):当一个线程修改了主内存中的变量,其他线程能够立即看到这个修改。JMM 能够保证 “工作内存” 的修改可以立刻原子性同步到主内存。通常的镇压手段是:
volatile。它强制线程在读取时必须从主内存拉取,写入时必须立刻推回主内存,并失效其他核心的缓存。 - 有序性 (Ordering):程序执行的顺序应当按照代码的先后顺序执行。主要的手段是
volatile(禁止指令重排)和 Happens-Before 原则。
终极契约:Happens-Before 原则
如果 JMM 只靠 volatile,程序员会累死。为了简化开发,JMM 定义了一套 “先行发生” (Happens-Before) 原则。只要符合这些规则,JMM 就保证操作 A 的结果对操作 B 可见,它是JMM的核心。
- 程序次序规则:同一个线程内,书写在前面的操作先行发生于后面的操作。
- 管程锁定规则:unlock 先行发生于后面对同一个锁的 lock。
- volatile 变量规则:对一个 volatile 变量的写操作,先行发生于后面对这个变量的读操作。
- 线程启动规则:Thread 对象的 start() 先行发生于此线程的每一个动作。
1 | // 规则1:程序顺序规则(单线程内) |
所以总结起来,JMM 本质就是硬件与程序员之间的一份 “契约合同”——只要你按照我的规则(关键字/原则)写代码,我就能保证结果不出错,剩下的性能优化我偷偷搞定。
JMM的本质是:
- 一个数学规范:形式化定义了多线程下什么是”正确”的执行
- 硬件抽象层:在多样的硬件内存模型之上提供统一行为
- 编译器契约:规定哪些优化是允许的
- 程序员承诺:正确使用同步原语,就能得到期望的行为
JMM的三大支柱:
Happens-Before:可见性的逻辑基础内存屏障:实现Happens-Before的物理机制原子操作:保证操作的不可分割性
JMM的最终目标:让Java程序员在享受高性能的同时,不需要理解底层硬件的复杂内存模型。你只需要遵循JMM的规则(使用正确的同步),JVM和硬件会保证程序在所有平台上的正确性。
JMM 内存操作原语
在 JMM(Java 内存模型)的底层设计中,为了实现 主内存 与 工作内存 之间的变量同步,定义了 8 种原子操作。你可以把这 8 种操作想象成 “主仓库” 与 “私人办公室” 之间搬运货物的装卸标准。虽然在现代 HotSpot 源码中它们已被更底层的内存屏障(Memory Barrier)所取代,但在逻辑模型上,它们依然是理解并发协议的基石。这 8 种操作必须成对或按顺序出现,才能保证数据的不丢失。
↑
↓
1. Read → Load: 必须按顺序将变量从主存载入工作内存副本。
2. Store → Write: 必须按顺序将工作内存修改同步回主存实体。
volatile 的本质:普通的读写可能在 assign 后就停了,而 volatile 保证了 assign-store-write 和 read-load-use 都是连贯的原子动作。
synchronized 的双重作用:Lock 时清空工作内存,强制从主存 read-load;Unlock 前强制执行 store-write 刷回主存。
JMM内存操作原语执行准则:
- 不允许 read 和 load、store 和 write 单独出现:你不能只从仓库搬货(read)而不进办公室门(load)。必须成对出现,保证搬运完整。
- 不允许线程丢弃最近的 assign 操作:只要你在办公室改了值(assign),就必须同步回仓库(store/write)。
- 不允许无原因地同步回主内存:如果没发生 assign,不允许无故把值刷回主内存。
- 变量必须在主内存诞生:对一个变量进行 use 或 store 之前,必须先经过 load 或 assign。简单说就是你不能凭空变出一个变量。
- lock 和 unlock 的同步契约(核心):
- 对一个变量执行 lock,会清空工作内存中此变量的值。所以 use 之前必须重新 load。(这保证了可见性)
- 对一个变量执行 unlock 之前,必须先把值同步回主内存(执行 store 和 write)。(这保证了持久性)
在早期的 Java 规范中,这 8 种操作是核心。但随着硬件架构的演进,这种模型越来越显得过于死板。现代 JVM(如 HotSpot)已经将这些逻辑简化为 Happens-Before 原则。底层映射:
- lock/unlock:对应字节码的 monitorenter/monitorexit。
- read/load/use 的组合受 volatile 标记影响,强制插入 Load Barrier。
- assign/store/write 的组合受 volatile 影响,强制插入 Store Barrier。
内存屏障及其硬件实现
要镇压 CPU 的 “乱序心魔”,Java 依靠的是一套精密的手动挡工具——内存屏障(Memory Barrier)。内存屏障是一组 CPU 指令,它的作用是:禁止屏障两侧的指令重排序,并强制刷新处理器缓存。
四种内存屏障:
1 | LoadLoad屏障(LL): load1; LoadLoad; load2 |
不同CPU架构的实现:
1 | #### x86架构: |
volatile 和 synchronized
首先 volatile 是轻量级的强制规约,它的核心原理是 JMM 屏障插入策略。
volatile 如何保证可见性?
- 写操作:在每行 volatile 写之后插入一个 StoreLoad 屏障。这会强制把工作内存的 assign 结果执行 store-write 刷回主存,并让其他 CPU 核心的缓存行失效。
- 读操作:在每行 volatile 读之前插入 Load 屏障。这会强制执行 read-load,从主存拉取最新值,而不是用办公室(工作内存)里的旧副本。
volatile 如何禁止重排序?
JIT 编译器在生成字节码时,会严格遵循以下守则:
- 在 volatile 写之前,插入 StoreStore(禁止上面的普通写和它重排)。
- 在 volatile 写之后,插入 StoreLoad(禁止下面的读写和它重排)。
- 在 volatile 读之后,插入 LoadLoad 和 LoadStore(禁止下面的读写爬到它上面去)。
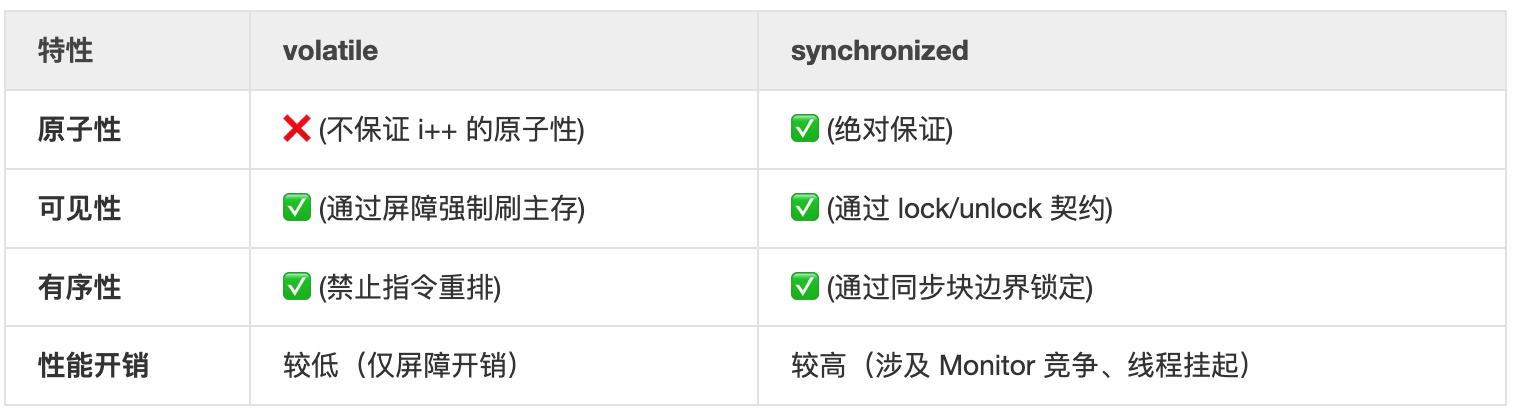
对于 synchronized,它是重量级的管程保护,其底层是基于 ObjectMonitor 的 lock 和 unlock 操作,它对三大特性的保证更 “暴力”:
synchronized 如何保证原子性?
- 原理:通过 monitorenter 和 monitorexit 指令。
- 本质:在同一时刻,只有一个线程能持有 ObjectMonitor。既然只有一个线程在跑这段代码,那它内部怎么重排、怎么读写,对外界来说都是一个不可分割的整体。
synchronized 如何保证可见性?
- 契约1:JMM 规定,对一个变量执行 unlock 之前,必须先把变量 store-write 回主存。
- 契约2:对一个变量执行 lock 时,必须清空工作内存,重新从主存 read-load 最新值。
- 结果:这就形成了一个天然的 “刷新” 机制。
synchronized 如何禁止重排序?
- 内部:synchronized 不禁止块内部的代码重排序(只要不影响单线程执行结果)。
- 外部:它保证了块内部的代码不会 “越界” 跑到 synchronized 块外面去。
- 原理:lock 操作自带 Acquire 语义(类似 LoadLoad + LoadStore),unlock 自带 Release 语义(类似 StoreStore + LoadStore)。这确保了临界区内的指令被 “锁” 在两个屏障之间。
一句话总结:volatile 是通过在代码里插 “隔离带(屏障)” 来实现有序;而 synchronized 是通过 “锁大门(Monitor)” 并规定 “进门带新货、出门留新货” 的规矩来实现同步。
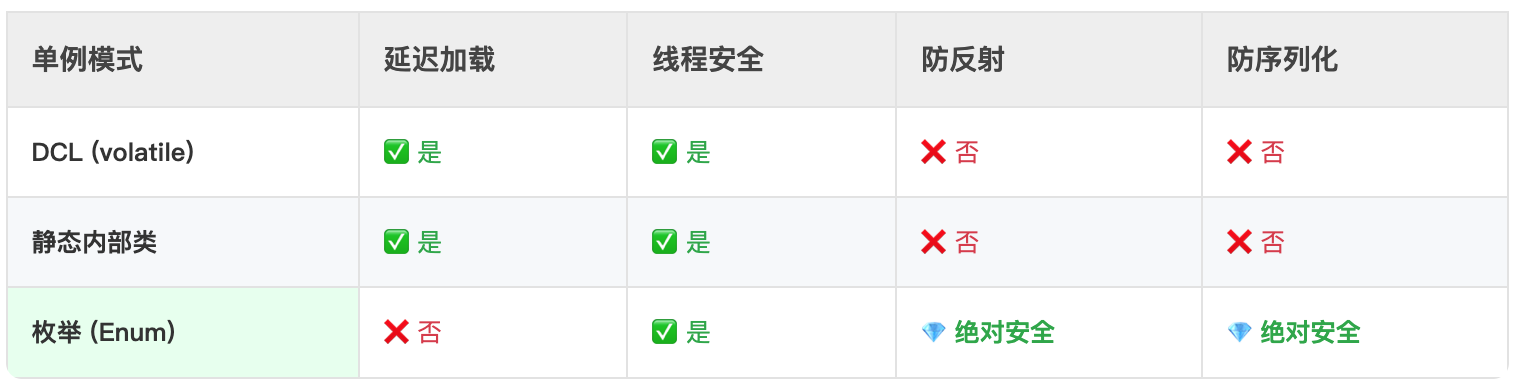
经典DCL和单例模式案例
双重检查锁实现
DCL 标准代码实现:
1 | public class Singleton { |
我们将聚焦于 instance = new Singleton(); 这行代码,看它在底层是如何被 “肢解” 的。在底层,new 一个对象并不是原子操作,它会被拆解为三条伪指令:
- 分配内存:在堆上开辟一块空间(Memory),在堆中开辟区域,值全为 0。
- 初始化对象:执行构造函数,填充字段(Init)。
- 地址赋值:将 instance 引用指向这块内存地址(Write)。
如果没有 volatile,CPU 可能会为了 “流水线不打断”,将 步骤 2 和 步骤 3 进行对调(重排序)。灾难发生的时间轴:
- 时刻 T1(线程 A):执行了步骤 1,内存分配完毕。
- 时刻 T2(线程 A):执行了重排后的步骤 3(地址赋值)。
- 结果:此时 instance 变量已经指向了那块内存,它不再是 null。
- 隐患:此时步骤 2(构造函数)还没跑,内存里全是 “毛坯房”。
- 时刻 T3(线程 B):正好执行到 getInstance() 的第一次检查 (A)。
- 动作:线程 B 发现 instance != null。
- 动作:线程 B 直接 return instance。
- 时刻 T4(线程 B):拿到 instance 后调用 instance.doSomething()。
- 结果:报错!因为对象还没初始化,内部成员变量可能全是空指针或默认值。
当你给 instance 加上 volatile,编译器会在生成的指令序列中插入 StoreStore 屏障。
1 | [指令 1] 分配内存 |
- 物理效果:屏障强制要求 CPU 必须先完成 “装修(初始化)”,才能挂上 “门牌号(地址赋值)”。
- 可见性效果:屏障还会触发 StoreLoad,确保线程 A 挂上的门牌号,线程 B 只要一抬头(读操作)就一定能立刻看到最新的,而不是去读自己缓存里的旧数据。
静态内部类实现
现代 Java 中,单例的实现,除了 DCL 之外,另一种更优雅、性能更高且天然线程安全的单例写法——静态内部类 也可以实现,它不需要 synchronized,也不需要 volatile:
1 | public class Singleton { |
这场 “白嫖” 的核心逻辑在于 JVM 的类加载机制(Class Loading),特别是它对静态变量初始化的保障。
A. 延迟加载 (Lazy Loading) —— 借用了“被动引用”
- 原理:在 Java 中,外部类被加载时,并不会触发内部类的加载。
- 过程:当你调用 Singleton.class 或者 Singleton 的其他静态方法时,Holder 类依然处于 “沉睡” 状态。只有第一次调用 getInstance() 并访问 Holder.INSTANCE 时,JVM 才会发现:“喔,我得去加载 Holder 类并初始化它的静态成员了。”
- 结果:完美实现了按需加载,不占内存。
B. 线程安全 (Thread Safety) —— 借用了 <clinit> 的原子性
- 原理:虚拟机会保证一个类的 <clinit>() 方法(类构造器,负责初始化静态变量)在多线程环境中被正确加锁、同步。
- 过程:如果多个线程同时尝试初始化 Holder 类,JVM 会确保只有一个线程去执行初始化动作,其他线程都要阻塞等待,直到初始化完成。
- 结果:既然初始化过程是 JVM 原生同步的,那么 new Singleton() 的过程就是天然线程安全的,绝对不会出现 DCL 中那种“半成品对象”的问题。
枚举单例方式实现
上述两种单例的写法——双重检查锁 和 静态内部类,仍然有一个可以改进的点,那就是它们的单例可能被反射/序列化破坏。我们通常会使用另一种 枚举单例 的方法来解决这个问题,枚举单例也被《Effective Java》作者 Joshua Bloch 称为实现 Singleton 的最佳方法,它的 “硬核” 不在于代码多复杂,而在于它直接在 JVM 运行规范和 Java 编译指令两个维度上封死了所有退路。
1 | /** |
JMM的最新发展
Java 9+的改进:
1 | // Java 9引入VarHandle,提供更精细的内存控制 |
Project Loom 和 JMM:
1 | // 虚拟线程(协程)对JMM的影响 |